สมัครเรียนโทร. 085-350-7540 , 084-88-00-255 , ntprintf@gmail.com

สุดยอด AI จาก Google ที่เปิดตัวมาพร้อมกับความสามารถที่เมื่อ 5 ปีที่แล้วต้องเขียน Code เป็น 1000 บรรทัดและยังไม่ Stable แต่ตอนนี้ทำได้ง่าย ๆ ด้วย Code แค่ 15 บรรทัด และยังสามารถรันบนหน้าเว็บ รันบน Android หรือรันใน Computer ตั้งโต๊ะที่บ้านของท่านด้วยเทคนิค Deep learning สุดล้ำที่มีการพัฒนาอย่างก้าวกระโดด
ในบทความนี้เป็นการแสดงเทคโนโลยีให้ท่านเห็นความสุดยอดของ AI ที่เราอยากจะชวนทุกคนมาตั้งคำถามกับตัวเองว่าในเมื่อ AI มันล้ำขนาดนี้ ท่านในฐานะนักธุรกิจที่มีความฝันอยากจะสร้างสิ่งที่ยิ่งใหญ่ในอนาคตจะต้องสร้างอะไร ท่านมี Idea ที่จะเปลี่ยน Code กระจอก ๆ ในหน้านี้เป็นเงิน 8 หลักในหน่วยบาทหรือ USD ได้อย่างไร และ Application อะไรที่ท่านจะสามารถสร้างได้จาก AI ตัวนี้
ท่านอาจจะคิดว่า AI เป็นเรื่องไกลตัวแต่จริง ๆ แล้วตั้งแต่เกิดมา หยิบ Smart phone ไถฟีดเฟซบุ๊ก ท่านก็ได้เจอกับ AI ประมาณ 3 ตัวแล้ว
บทความนี้เป็นบทความในชุด “ตรวจจับสารพัดสิ่งด้วย MediaPipe” ชุดบทความที่จะชวนท่านผู้อ่านมาลองใช้งาน Machine Learning บนเครื่องคอมพิวเตอร์ของเราเองเพื่อตรวจจับสารพัดสิ่ง เช่น มือ คน สัตว์ สิ่งของ ไปจนถึงอิริยาบถของเรา บทความชุดนี้ประกอบไปด้วย
แต่ละบทความจะเป็นบทความสั้น ๆ พร้อม Code ที่ทาง EPT ปรับให้ง่ายที่สุดเพื่อให้ทุกคนนำไปใช้ได้เลยแม้จะไม่มีพื้นฐาน Python มาก่อน (แต่ต้องมีพื้นฐานการใช้งานคอมพิวเตอร์อยู่สักหน่อยนะครับ)
สำหรับใครที่ต้องการเรียนรู้เกี่ยวกับการเขียน การสร้าง AI โดยละเอียดเรียนเชิญได้ที่ Course AI701 แต่ถ้าท่านยังไม่มีพื้นฐานการเขียนโปรแกรมเลยสามารถลงเรียน คอร์ส Python + Web Programming + Machine Learning (PY203) ได้ ซึ่งจะพาท่านไปเริ่มเรียนเขียนโปรแกรมตั้งแต่รู้จักเลขฐาน 2 รู้ว่าคอมพิวเตอร์เครื่องแรกของโลกทำงานอย่างไร เรียนภาษาเขียนโปรแกรม Python เรียนการเขียน Web HTML CSS JavaScript AJAX jQuery Bootstrap และอื่น ๆ อีกมากมาย จนไปจบที่ AI เนื้อหาอัดแน่นกว่า 200 ชั่วโมง และมีคอร์สแถมยิบย่อยตามฤดูกาลอีก เรียกได้ว่าคุ้มสุด จากไม่รู้อะไรจะเปลี่ยนมาทำงานด้าน Programmer เลยก็ยังได้ หรือจากไม่รู้อะไรจะเปลี่ยนสายมาทำ Data science ก็ยังชิล ๆ
Human pose estimation เป็นกระบวนการของการประมาณท่าทางของมนุษย์ในรูปภาพหรือวิดีโอ ซึ่งคอมพิวเตอร์จะจับจุดสำคัญต่าง ๆ ของมนุษย์ เช่น ตา จมูก ลำตัว แขน ขา หรือข้อต่อต่าง ๆ แล้วตรวจจับท่าทางของมนุษย์จากตำแหน่งของจุดเหล่านั้น ซึ่งมีประโยชน์ตั้งแต่ใช้ในการวินิจฉัยท่าทางการเดินในทางการแพทย์ไปจนถึงการทำแอนิเมชันในวงการบันเทิง
การประมาณท่าทางของมนุษย์นี้เป็นหนึ่งในปัญหาหลักของงานด้านภาพของคอมพิวเตอร์ แม้จะมีการวิจัยกันมาหลายสิบปีแล้วแต่จนถึงปัจจุบันก็ยังไม่มีวิธีแก้ปัญหาที่น่าพอใจออกมา มีหลายปัจจัยที่ทำให้งานนี้เป็นปัญหาที่ยากและท้าทาย เช่น มุมกล้อง สภาพแสง ลักษณะร่างกายของมนุษย์ที่แตกต่างกัน การที่ส่วนของร่างกายบางส่วนซ้อนทับกันทำให้มองไม่เห็นส่วนที่ถูกบังอยู่ หรือการสูญเสียข้อมูล 3 มิติเมื่อถ่ายภาพ เป็นต้น
ภาพยนตร์ / แอนิเมชัน
ตัวอย่างที่ดูจะใกล้ตัวและผ่านตาทุกท่านมาแล้วมากที่สุดน่าจะเป็นการประยุกต์ใช้ในการผลิตภาพยนตร์และแอนิเมชัน ท่านเคยดูภาพยนตร์หรือแอนิเมชันพวกนี้หรือไม่?
เบื้องหลังตัวละครที่เมื่อปรากฏในหน้าจอแล้วไม่ใช่คนจริงในภาพยนตร์และแอนิเมชันทุกเรื่องที่ยกตัวอย่างมานั้นตอนถ่ายทำจะใช้คนจริงเป็นผู้แสดง แล้วใช้โปรแกรมสั่งให้ตัวละครหรือตัวการ์ตูนที่ออกแบบไว้ในคอมพิวเตอร์ขยับหรือทำสีหน้าตามผู้แสดงอีกที ซึ่งกระบวนการที่จะแปลการเคลื่อนไหวของผู้แสดงจากโลกจริงให้เป็นข้อมูลดิจิทัลที่คอมพิวเตอร์เพื่อให้ตัวละครขยับตามนี้ก็คือ Motion Capture (mo-cap)
วิดีโอด้านล่างนี้แสดงเบื้องหลังการถ่ายทำตัวละครกอลลัมจากเรื่องเดอะลอร์ดออฟเดอะริงส์ ซึ่งแอนดี้ เซอร์คิส (Andy Serkis) ผู้ที่คนในวงการยกให้เป็น King of mo-cap เป็นผู้แสดงและพากย์เสียง
ผมเคยเขียนเกี่ยวกับเรื่องประโยชน์ของการนำ AI มาใช้ทำ Motion Capture และสาธิตวิธีการทำให้ดูไว้ในบทความ AI104 - Video to BVH สร้างไฟล์ท่าเต้นสุดคิวท์ให้ตัวการ์ตูนเต้นตามใน 1 คำสั่ง ลองไปอ่านกันดูนะครับ
เกม
ในหลาย ๆ เกมก็มีการนำ Motion Capture มาใช้เพื่อกำหนดท่าทางให้ตัวละครเช่นเดียวกับในภาพยนตร์หรือแอนิเมชัน นอกจากนี้ยังมีการใช้เทคนิคการประมาณท่าทางเพื่อจับท่าทางของผู้เล่นเพื่อบังคับตัวละครในเกมให้ออกท่าทางต่าง ๆ ตามอีกด้วย

การออกกำลังกาย / การทำกายภาพบำบัด
บางคนอาจจะสงสัยว่าทำไมสองอย่างนี้มาอยู่ในหัวข้อเดียวกันได้ สิ่งที่เหมือนกันในสองกิจกรรมนี้ก็คือผู้ออกกำลังกายและผู้ที่ทำกายภาพบำบัดจำเป็นต้องทำท่าทางให้ถูกต้องตามแบบแผนเพื่อประสิทธิภาพที่สูงสุด ถ้าเป็นสมัยก่อนเราก็ต้องจ้างเทรนเนอร์หรือผู้เชี่ยวชาญเพื่อให้ช่วยดูและปรับท่าให้เราใช่ไหมครับ แต่หากใช้ Human pose estimation แล้วเราก็จะสามารถรู้ได้ทันทีว่าทำท่าต่าง ๆ ผิดอย่างไรและควรปรับตรงไหนได้ที่บ้านของเราเองเลย ซึ่งช่วยประหยัดค่าใช้จ่ายของทั้งผู้ออกกำลังกายและผู้ป่วยไปได้อีกมาก และยังช่วยลดปัญหาเรื่องบุคลากรทางการแพทย์ไม่พอเพียงด้วย

ดูแลผู้ป่วยและผู้สูงอายุ
นอกจากจะใช้ประเมินท่าทางเพื่อตรวจสอบว่าผู้ป่วยหรือผู้สูงอายุกำลังปฏิบัติตามการรักษาหรือการฟื้นฟูที่แพทย์สั่งหรือไม่คล้าย ๆ กับกรณีกายภาพบำบัดแล้ว ยังนำมาช่วยในเรื่องการประเมินการเคลื่อนไหวหรือท่าทางของผู้ป่วยหรือผู้สูงอายุได้อีกด้วย เช่น เคลื่อนไหวปกติไหม ตอนเดินร่างกายสมดุลดีไหม หรือประเมินความเสี่ยงของอุบัติเหตุอย่างหกล้มหรือสะดุด เป็นต้น

ป้องกันเหตุรุนแรงและอาชญากรรม
การประเมินท่าทางของมนุษย์สามารถนำมาใช้ช่วยเสริมระบบรักษาความปลอดภัย เช่น ใช้ตรวจจับพฤติกรรมที่เป็นอันตรายหรือเสี่ยงต่อความปลอดภัยต่อบุคคลอื่นอย่างท่าโจมตีหรือการถืออาวุธในที่สาธารณะ ใช้ระบุและติดตามบุคคลที่สงสัยโดยตรวจสอบการเคลื่อนไหวและรูปร่างของบุคคลในวิดีโอหรือภาพถ่าย เป็นต้น ตัวอย่างภาพด้านล่างเป็นภาพจาก AI Guardman ของ NTT Docomo ซึ่งเป็น AI ที่ช่วยตรวจจับและระบุพฤติกรรมที่น่าสงสัยว่าจะมีการขโมยของเกิดขึ้น เมื่อพบจะแจ้งให้เจ้าของร้านทราบเพื่อเฝ้าระวังต่อไป

และอีกมากมาย
การศึกษาและวิจัยเกี่ยวกับการประมาณท่าทางของมนุษย์มีมานานหลายสิบปีแล้ว เราจะมาดูวิวัฒนาการและเทคโนโลยีที่น่าสนใจกัน
Monocular Human pose estimation
ยุคแรกของงานวิจัยเริ่มในช่วงคริสต์ทศวรรษ 1960 ช่วงนั้นนักวิจัยเริ่มพัฒนาวิธีการในการระบุและติดตามท่าทางของมนุษย์โดยใช้กล้องตัวเดียวหรือใช้อินพุตเป็นรูปภาพเดียว จากนั้นจะใช้คอมพิวเตอร์วิทัศน์ (Computer vision) และเทคนิคการรู้จำแบบ (Pattern recognition) เพื่อประมาณท่าทางในรูปภาพนั้น แต่ในสมัยนั้นวิธีการนี้มีข้อจำกัดเนื่องจากคอมพิวเตอร์ยังขาดพลังในการคำนวณและข้อมูลอยู่ รวมทั้งยังมีปัญหาหลักคือการสูญเสียข้อมูล 3 มิติไปอีกด้วย
Multi-camera
เมื่อการใช้กล้องเดียวมีปัญหา วิธีที่นิยมที่สุดในการประมาณการเคลื่อนไหวในงานวิจัยหรือในอุตสาหกรรมที่ต้องการความแม่นยำสูง คือการใช้กล้องหลายตัวเพื่อจับภาพจากมุมมองต่าง ๆ พร้อมกัน เมื่อรวมข้อมูลจากกล้องหลายตัวเข้าด้วยกันก็จะทำให้สามารถระบุตำแหน่งข้อต่อของร่างกายได้แม่นยำยิ่งขึ้น นำไปสู่การประมาณท่าทางที่ดีขึ้น วิธีนี้เป็นวิธีที่ใช้ทำ Motion capture ในอุตสาหกรรมภาพยนตร์และแอนิเมชันที่กล่าวไปในหัวข้อก่อนหน้านี้นั่นเอง แต่แน่นอนว่าแลกมาด้วยค่าใช้จ่ายที่สูงและการตั้งค่าที่ยุ่งยากกว่ากล้องตัวเดียว

Kinect
ในปี 2010 Microsoft ได้เปิดตัว Kinect ขึ้นมา ซึ่งถือเป็นการปฏิวัติการประมาณท่าทางของมนุษย์ไปในอีกรูปแบบหนึ่งคือการนำเซนเซอร์ความลึกเข้ามาช่วยด้วย การรวมกล้อง RGB เข้ากับเซ็นเซอร์ความลึกนี้ทำให้สามารถประมาณท่าทาง 3 มิติได้แม่นยำมากขึ้น เทคโนโลยีนี้ช่วยให้สามารถติดตามท่าทางของมนุษย์ได้แบบเรียลไทม์โดยไม่ต้องใช้การตั้งค่ากล้องหลายตัวที่ซับซ้อน แม้ว่าในตอนแรก Microsoft จะสร้าง Kinect ขึ้นมาเพื่อใช้กับเครื่องเกม Xbox 360 แต่ด้วยความสามารถในการตรวจจับท่าทางที่แม่นยำของมัน ราคา และการตั้งค่าที่ง่ายดาย ทำให้มีผู้นำไปใช้ในงานวิจัยมากทีเดียว

LiDAR
ในสมัยหลัง ๆ ได้มีเทคโนโลยีที่เรียกว่า Light Detection and Ranging (LiDAR) ออกมา LiDAR จะปล่อยลำแสงเลเซอร์ไปกระทบพื้นผิวหรือวัตถุต่าง ๆ เพื่อวัดระยะทางและสร้าง Point Clouds ของสภาพแวดล้อมโดยรอบในรูปแบบ 3 มิติโดยละเอียด ทำให้สามารถใช้ประเมินท่าทางของมนุษย์ได้อย่างแม่นยำแม้ในสภาพแวดล้อมที่สภาพแสงไม่เอื้ออำนวย ในช่วงแรกที่ออกมานั้น LiDAR มีราคาสูงมาก แต่ในปัจจุบันนี้ราคาของ LiDAR ลดลงอย่างมาก ทำให้เป็นเทคโนโลยีที่เราเห็นทั่วไปตั้งแต่หุ่นยนต์ดูดฝุ่นตามบ้านเรือนไปจนถึงยานพาหนะไร้คนขับตามท้องถนน
ปัจจุบันทำได้ง่าย ๆ ด้วย Deep learning และ Google MediaPipe Pose Landmarker
หลังจากการกำเนิดของ Deep learning โดยเฉพาะ Convolutional Neural Networks (CNNs) ทำให้งานวิจัยเกี่ยวกับการประมาณท่าทางของมนุษย์พลิกโฉมอีกครั้ง มีผู้พัฒนาโมเดล Deep learning ออกมามากมายซึ่งโมเดลเหล่านี้สามารถประมาณท่าทางของมนุษย์ได้อย่างแม่นยำโดยใช้อินพุตเป็นรูปภาพเพียงรูปเดียวเหมือน Monocular Human pose estimation ในยุคแรก
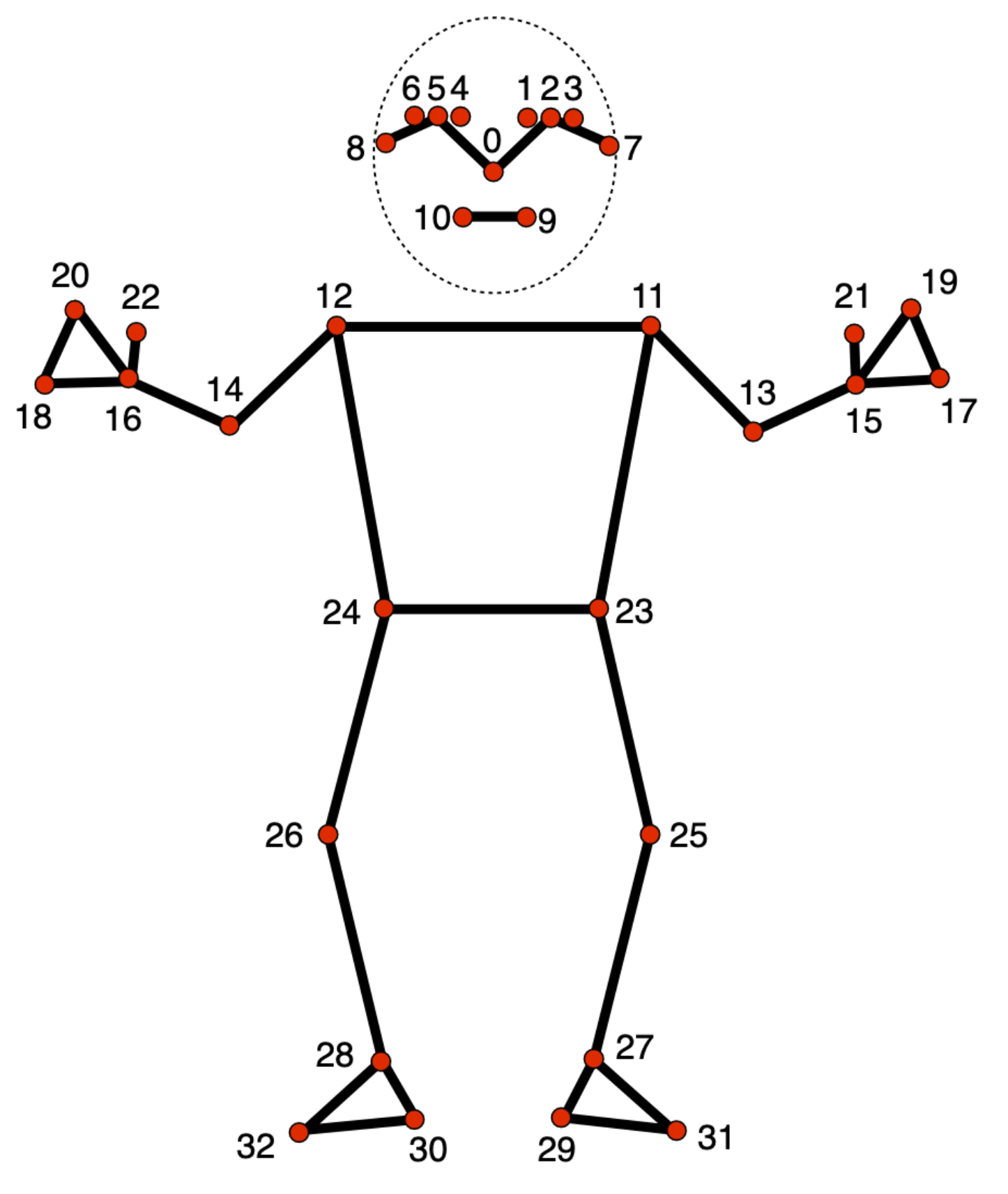
ในบทความนี้ เราจะสาธิตการใช้งาน MediaPipe Pose Landmarker ของ Google ซึ่งจะช่วยให้เราตรวจจับจุดสำคัญต่าง ๆ ของร่างกายมนุษย์ในรูปภาพหรือวิดีโอหรือจากกล้องเว็บแคมแบบเรียลไทม์ได้อย่างง่ายดาย โมเดลนี้จะประมาณจุดสำคัญของร่างกายมนุษย์ทั้งหมด 33 จุดดังต่อไปนี้
สิ่งที่จำเป็นต้องติดตั้งในคอมพิวเตอร์ ได้แก่
สามารถดูวิธีติดตั้งได้จากบทความ AI105 - Hand Landmarks Detection Using MediaPipe
ข้อควรระวัง
Code ที่ใช้ในบทความนี้ได้รับการทดสอบบนเครื่อง Windows 10 64-bit ที่ติดตั้ง Python และ Package ต่าง ๆ ตามเวอร์ชันที่กำหนดไว้ในบทความนี้ ดังนั้นหากผู้เรียนใช้อะไรบางอย่างคนละเวอร์ชันกับที่กำหนดไว้ก็จะมีโอกาสสูงที่จะรันแล้วเกิดข้อผิดพลาดบางประการ สำหรับ Package (ทั้งที่ใช้และไม่ใช้) ทั้งหมดที่มีในเครื่องคอมพิวเตอร์ที่ใช้ทดสอบจะสรุปให้ดูที่ท้ายบทความ*
1. เปิดโปรแกรม Python IDE ขึ้นมาแล้วเขียน code ดังต่อไปนี้
#import library ที่ใช้
import numpy as np
import mediapipe as mp
import cv2
import os
#ทดสอบ พิมพ์ก่อนว่าตอนนี้เราอยู่ที่ directory ไหน
print(os.getcwd())
from mediapipe import solutions
from mediapipe.framework.formats import landmark_pb2
def draw_landmarks_on_image(rgb_image, detection_result):
pose_landmarks_list = detection_result.pose_landmarks
annotated_image = np.copy(rgb_image)
# Loop through the detected poses to visualize.
for idx in range(len(pose_landmarks_list)):
pose_landmarks = pose_landmarks_list[idx]
# Draw the pose landmarks.
pose_landmarks_proto = landmark_pb2.NormalizedLandmarkList()
pose_landmarks_proto.landmark.extend([
landmark_pb2.NormalizedLandmark(x=landmark.x, y=landmark.y, z=landmark.z) for landmark in pose_landmarks
])
solutions.drawing_utils.draw_landmarks(
annotated_image,
pose_landmarks_proto,
solutions.pose.POSE_CONNECTIONS,
solutions.drawing_styles.get_default_pose_landmarks_style())
return annotated_image
from mediapipe.tasks import python
from mediapipe.tasks.python import vision
# STEP 2: Create an PoseLandmarker object.
base_options = python.BaseOptions(model_asset_path='pose_landmarker.task')
options = vision.PoseLandmarkerOptions(
base_options=base_options,
output_segmentation_masks=True)
detector = vision.PoseLandmarker.create_from_options(options)
webcam = cv2.VideoCapture(0)
image = webcam.read()
mp_hands = mp.solutions.hands
hands = mp_hands.Hands()
mp_draw = mp.solutions.drawing_utils
while True:
success, image = webcam.read()
image_rgb = cv2.cvtColor(image,cv2.COLOR_BGR2RGB)
#results = hands.process(image_rgb)
# STEP 3: Load the input image.
image = mp.Image(image_format=mp.ImageFormat.SRGB, data=image_rgb)
# STEP 4: Detect pose landmarks from the input image.
detection_result = detector.detect(image)
# STEP 5: Process the detection result. In this case, visualize it.
annotated_image = draw_landmarks_on_image(image.numpy_view(), detection_result)
cv2.imshow("Image",cv2.cvtColor(annotated_image, cv2.COLOR_RGB2BGR))
k =cv2.waitKey(1)
if k == 27:
break
cv2.destroyAllWindows()
2. เมื่อสั่งรัน จะได้หน้าต่างสำหรับแสดงผลภาพจากกล้องเว็บแคมแบบเรียลไทม์พร้อมทั้งแสดงตำแหน่งสำคัญของท่าทางดังภาพตัวอย่าง

เพียงเท่านี้เราก็จะได้โปรแกรมตรวจจับท่าทางของคนแบบเรียลไทม์ด้วย Python แล้ว นอกจากจะใช้งานเป็นโปรแกรมบนเครื่องได้แล้ว เรายังสามารถใช้ MediaPipe ทำแอปพลิเคชันสำหรับแอนดรอยด์ หรือใช้งานบนเว็บก็ได้ ใครสนใจสามารถดูตัวอย่างได้ที่นี่
จากบทความนี้และบทความก่อน ๆ จะเห็นได้ว่าความก้าวหน้าอย่างต่อเนื่องที่ขับเคลื่อนโดยนวัตกรรมทางเทคโนโลยีทำให้ในปัจจุบันทุกคนสามารถเข้าถึงเทคโนโลยีที่มีความซับซ้อนและมีราคาสูงในสมัยก่อนได้อย่างง่ายดายมากขึ้น แม่นยำมากขึ้น และราคาถูกยิ่งขึ้น นอกจากนี้ยังใช้งาน AI ให้ทำงานแทนมนุษย์ได้ในอีกหลาย ๆ งานด้วย อีกไม่นานเราจะได้พบกับเทคโนโลยีเหล่านี้ซึ่งใช้งานในสาขาต่าง ๆ เช่น วิทยาการหุ่นยนต์ การโต้ตอบระหว่างมนุษย์กับคอมพิวเตอร์ การวิเคราะห์กีฬา การดูแลสุขภาพ โลกเสมือนจริง และอีกมากมายอยู่รอบตัวเราทั้งที่รู้ตัวและไม่รู้ตัว ถึงเวลาแล้วหรือยังที่เราจะตื่นตัวและเปิดใจเรียนรู้เทคโนโลยีใหม่ ๆ เพื่อที่เราจะได้เป็นผู้ใช้งานมันให้ทำงานให้เรา ไม่ใช่ให้มันมาแทนที่เรา
สุดท้ายนี้สำหรับใครที่สนใจอยากทำ AI แต่ยังไม่มีพื้นฐานเขียนโปรแกรมมาก่อน ขอแนะนำคอร์ส Python + Web Programming + Machine Learning (PY203) ของทาง EPT ที่สอนแบบจัดเต็มตั้งแต่พื้นฐาน Python หรือหากมีพื้นฐาน Python แน่น ๆ อยู่แล้วแต่อยากเรียนเกี่ยวกับ AI แบบลงลึกถึงทฤษฎีก็ขอแนะนำคอร์ส Machine Learning (AI701) ครับ
พิเศษวันนี้! หากสมัครคอร์ส Python + Web Programming + Machine Learning (PY203) แล้วแจ้งผ่านทางกล่องข้อความของเพจ Expert.Programming.Tutor ว่ามาสมัครเพราะอ่านบทความนี้ ทางเราจะแถมคอร์ส Computer Engineering Essential (COM101) และคอร์ส SUPER USER (SU101) ที่จะช่วยให้ท่านเข้าใจตั้งแต่พื้นฐานคอมพิวเตอร์ไปจนถึงเรื่อง Command Line การใช้งาน Git และ Linux อย่างลึกซึ้งให้ไปเรียนด้วยแบบฟรี ๆ เลยครับ
แล้วพบกันใหม่บทความหน้าครับ
[1] https://developers.google.com/mediapipe
[2] https://developers.google.com/mediapipe/solutions/vision/pose_landmarker
[3] https://archive.interconf.center/index.php/conference-proceeding/article/view/3213/3244
* เครื่องที่ใช้ทดสอบในบทความนี้เป็น Windows 10 64-bit และมี Package ต่าง ๆ ในเครื่องดังนี้
| Package Version --------------------- -------- absl-py 1.4.0 asttokens 2.2.1 attrs 23.1.0 backcall 0.2.0 cffi 1.15.1 cloudpickle 2.2.1 colorama 0.4.6 comm 0.1.3 cycler 0.11.0 debugpy 1.6.7 decorator 5.1.1 executing 1.2.0 flatbuffers 23.5.26 fonttools 4.33.3 importlib-metadata 6.6.0 ipykernel 6.23.1 ipython 8.13.2 jedi 0.18.2 jupyter_client 8.2.0 jupyter_core 5.3.0 kiwisolver 1.4.2 matplotlib 3.5.2 matplotlib-inline 0.1.6 mediapipe 0.10.0 nest-asyncio 1.5.6 numpy 1.22.4 opencv-contrib-python 4.7.0.72 opencv-python 4.7.0.72 packaging 21.3 pandas 1.2.1 parso 0.8.3 pickleshare 0.7.5 Pillow 9.1.1 pip 23.1.2 platformdirs 3.5.1 prompt-toolkit 3.0.38 protobuf 3.20.3 psutil 5.9.5 pure-eval 0.2.2 pycparser 2.21 Pygments 2.15.1 pyparsing 3.0.9 python-dateutil 2.8.2 pytz 2022.2.1 pywin32 306 pyzmq 25.1.0 setuptools 56.0.0 six 1.16.0 sounddevice 0.4.6 spyder-kernels 2.4.3 stack-data 0.6.2 tornado 6.3.2 traitlets 5.9.0 typing_extensions 4.6.3 wcwidth 0.2.6 zipp 3.15.0 |
Tag ที่น่าสนใจ: ai pose_landmarks_detection mediapipe deep_learning human_pose_estimation motion_capture computer_vision machine_learning artificial_intelligence programming python web_development image_segmentation object_detection hand_landmarks_detection
หากมีข้อผิดพลาด/ต้องการพูดคุยเพิ่มเติมเกี่ยวกับบทความนี้ กรุณาแจ้งที่ http://m.me/Expert.Programming.Tutor
085-350-7540 (DTAC)
084-88-00-255 (AIS)
026-111-618
หรือทาง EMAIL: NTPRINTF@GMAIL.COM

Copyright (c) 2013 expert-programming-tutor.com. All rights reserved. | 085-350-7540 | 084-88-00-255 | ntprintf@gmail.com