สมัครเรียนโทร. 085-350-7540 , 084-88-00-255 , ntprintf@gmail.com
เรียนเขียนโปรแกรมง่ายๆ กับ Expert Programming Tutor ในบท Machine Learning - Train/Test
ในเนื้อหาบทนี้นักเรียนจะได้ฝึกเขียนเเละเรียนรู้เกี่ยวกับการทดสอบแบบจำลองโดยใช้ชุดการทดสอบ มันจะเป็นอย่างไรเรามาเรียนรู้กันเถอะ
ประมวลผลโมเดลของนักเรียน
ในการเรียนรู้ของเครื่องจักรเราสร้างแบบจำลองเพื่อทำนายผลลัพธ์ของเหตุการณ์บางอย่างเช่นในบทก่อนหน้าซึ่งเราคาดการณ์การปล่อย CO2 ของรถยนต์เมื่อเรารู้น้ำหนักและขนาดเครื่องยนต์ ในการวัดว่าแบบจำลองนั้นดีเพียงพอเราสามารถใช้วิธีการที่เรียกว่า Train / Test
Train / Test คืออะไร
เป็นวิธีการวัดความแม่นยำของแบบจำลองของนักเรียน เรียกว่า Train / Test เพราะนักเรียนแบ่งชุดข้อมูลออกเป็นสองชุด ชุดฝึกอบรมและชุดทดสอบ 80% สำหรับการฝึกอบรมและ 20% สำหรับการทดสอบ
-นักเรียนฝึกฝนโมเดลโดยใช้ชุดการฝึกอบรม
-นักเรียนทดสอบแบบจำลองโดยใช้ชุดการทดสอบ
-ฝึกอบรมโมเดลหมายถึงสร้างโมเดล
-ทดสอบแบบจำลองหมายถึงทดสอบความถูกต้องของแบบจำลอง
การเริ่มต้นด้วยชุดข้อมูล
เริ่มต้นด้วยชุดข้อมูลที่นักเรียนต้องการทดสอบ ชุดข้อมูลของเราแสดงลูกค้า 100 รายในร้านค้าและพฤติกรรมการซื้อของพวกเขา
ตัวอย่าง
|
import numpy |
ผลลัพธ์
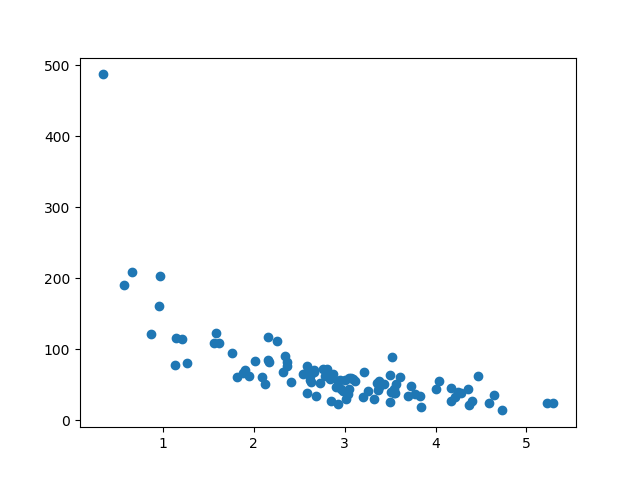
แกน x แสดงจำนวนนาทีก่อนตัดสินใจซื้อ
แกน y หมายถึงจำนวนเงินที่ใช้ในการซื้อ
แบ่งออกเป็น Train / Test
-ชุดฝึกอบรมควรเลือกแบบสุ่ม 80% ของข้อมูลต้นฉบับ
-ชุดทดสอบควรเหลือ 20%
|
train_x = x[:80] |
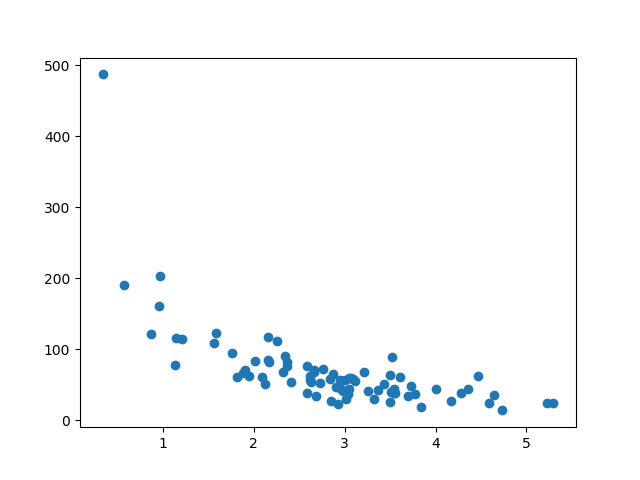
แสดงชุดการฝึกอบรม
แสดงพล็อตกระจายเดียวกันกับชุดการฝึกอบรม
ตัวอย่าง
|
import numpy |
ผลลัพธ์
ดูเหมือนว่าชุดข้อมูลดั้งเดิมดังนั้นจึงดูเหมือนเป็นการเลือกที่สมเหตุสมผล
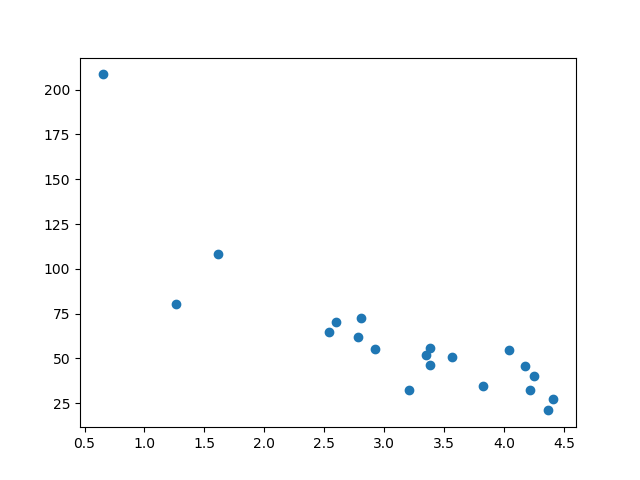
แสดงชุดการทดสอบ
เพื่อให้แน่ใจว่าชุดทดสอบไม่แตกต่างกันโดยสิ้นเชิงเราจะดูที่ชุดทดสอบเช่นกัน
|
import numpy |
ผลลัพธ์
ชุดทดสอบนั้นดูเหมือนกับชุดข้อมูลดั้งเดิม
ความเหมาะสมกับชุดข้อมูล
ชุดข้อมูลมีลักษณะอย่างไร ในความคิดของผม ผมคิดว่าแบบที่ดีที่สุดคือการถดถอยพหุนามดังนั้นเรามาวาดเส้นพหุนามถดถอย ในการวาดเส้นผ่านจุดข้อมูลเราใช้วิธีการ plot () ของโมดูล matplotlib
ตัวอย่าง
วาดเส้นการถดถอยพหุนามผ่านจุดข้อมูล
|
import numpy |
ผลลัพธ์
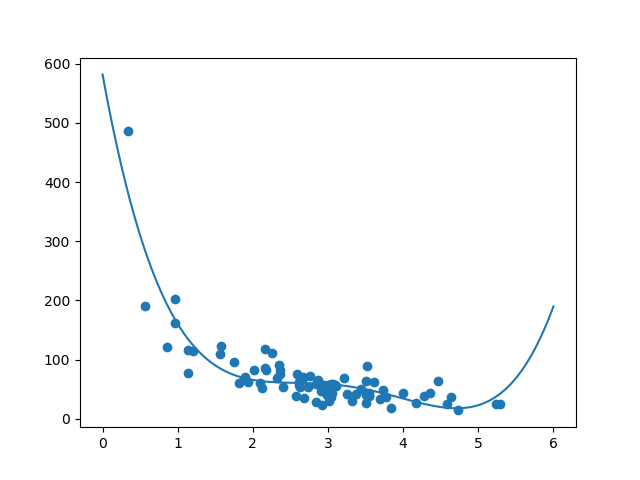
สามารถสำรองข้อเสนอแนะของเราเเละของชุดข้อมูลที่เหมาะสมกับการถดถอยพหุนามถึงแม้ว่ามันจะให้ผลลัพธ์แปลก ๆ แก่เรา ถ้าเราพยายามทำนายค่านอกชุดข้อมูล
ตัวอย่าง: สายระบุว่าลูกค้าที่ใช้เวลา 6 นาทีในร้านค้าจะซื้อสินค้ามูลค่า 200 นั่นอาจเป็นสัญญาณของการมีลูกค้ามากเกินไป แต่คะแนน R-squared ล่ะ? คะแนน R-squared เป็นตัวบ่งชี้ที่ดีว่าชุดข้อมูลของเราเหมาะสมกับแบบจำลองอย่างไร
R2
จำ R2 ได้หรือที่เรียกว่า R-squared?
มันวัดความสัมพันธ์ระหว่างแกน x และแกน y และช่วงค่าจาก 0 ถึง 1 โดยที่ 0 หมายถึงไม่มีความสัมพันธ์และ 1 หมายถึงเกี่ยวข้องโดยสิ้นเชิง
โมดูล sklearn มีวิธีการที่เรียกว่า rs_score () ที่จะช่วยเราหาความสัมพันธ์นี้
ในกรณีนี้เราต้องการวัดความสัมพันธ์ระหว่างนาทีที่ลูกค้าอยู่ในร้านและจำนวนเงินที่ใช้ไป
ตัวอย่าง
ข้อมูลการฝึกอบรมของเรามีความเหมาะสมในการถดถอยพหุนามอย่างไร
|
import numpy |
ผลลัพธ์
|
0.7988645544629795 |
หมายเหตุ: ผลลัพธ์ 0.799 แสดงว่ามีความสัมพันธ์ตกลง
นำชุดทดสอบเข้ามา
- ตอนนี้เราได้สร้างแบบจำลองที่ใช้ได้อย่างน้อยเมื่อมันมาถึงข้อมูลการฝึกอบรม
- ตอนนี้เราต้องการทดสอบโมเดลด้วยข้อมูลการทดสอบเช่นกันเพื่อดูว่าให้ผลลัพธ์ที่เหมือนกันหรือไม่
ตัวอย่าง
ให้เราหาคะแนน R2 เมื่อใช้ข้อมูลการทดสอบ
|
import numpy |
ผลลัพธ์
|
0.8086921460343677 |
หมายเหตุ ผลลัพธ์ 0.809 แสดงว่าแบบจำลองนั้นเหมาะกับชุดการทดสอบและเรามั่นใจว่าเราสามารถใช้แบบจำลองเพื่อทำนายค่าในอนาคต
ทำนายค่า
ตอนนี้เราได้สร้างแบบจำลองของเราเรียบร้อยแล้วเราสามารถเริ่มทำนายค่าใหม่ได้
ตัวอย่าง
ลูกค้าที่ซื้อจะใช้เงินเท่าไหร่ถ้าเธอหรือเขาอยู่ในร้านเป็นเวลา 5 นาที?
|
import numpy |
ตัวอย่างคาดการณ์ว่าลูกค้าจะใช้จ่าย 22.88 ดอลลาร์ตามที่ดูเหมือนกับแผนภาพ
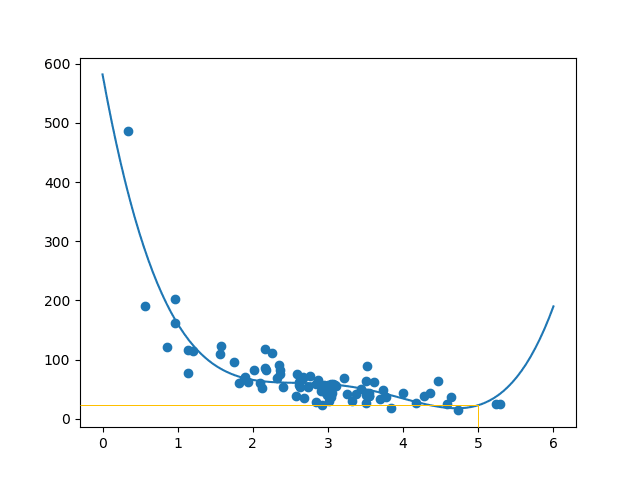
แปลจากhttps://www.w3schools.com/python/python_ml_train_test.asp
Tag ที่น่าสนใจ: machine_learning train test data_preparation model_training model_testing data_visualization regression_analysis python numpy matplotlib data_modeling r-squared sklearn
หากมีข้อผิดพลาด/ต้องการพูดคุยเพิ่มเติมเกี่ยวกับบทความนี้ กรุณาแจ้งที่ http://m.me/Expert.Programming.Tutor
085-350-7540 (DTAC)
084-88-00-255 (AIS)
026-111-618
หรือทาง EMAIL: NTPRINTF@GMAIL.COM

Copyright (c) 2013 expert-programming-tutor.com. All rights reserved. | 085-350-7540 | 084-88-00-255 | ntprintf@gmail.com