สมัครเรียนโทร. 085-350-7540 , 084-88-00-255 , ntprintf@gmail.com
เรียนเขียนโปรเเกรมง่ายๆกับ Expert Programming Tutor ในบท Machine Learning - Decision
ในบทนี้เราจะได้ทำความเข้าใจเกี่ยวกับต้นไม้ตัดสินใจ เเละเเนวคิดที่เเตกต่าง เพื่อให้ได้ผลลัพธ์ที่เเม่นยำ จะเป็นอย่างไรเรามาเรียนรู้กันเลย
ต้นไม้ตัดสินใจ
ในบทนี้เราจะแสดงวิธีสร้าง "ต้นไม้ตัดสินใจ" แผนภูมิการตัดสินใจเป็นแผนภูมิการไหลและสามารถช่วยนักเรียนตัดสินใจบนพื้นฐานของประสบการณ์ที่ผ่านมา ในตัวอย่างบุคคลจะพยายามตัดสินใจว่าเขา/เธอ ควรไปแสดงตลกหรือไม่ ดีที่คนในตัวอย่างของเราลงทะเบียนทุกครั้งที่มีการแสดงตลกในเมืองและลงทะเบียนข้อมูลบางอย่างเกี่ยวกับนักแสดงตลกและลงทะเบียนถ้า เขา/เธอ ควร ไป หรือ ไม่
|
Age |
Experience |
Rank |
Nationality |
Go |
|
36 |
10 |
9 |
UK |
NO |
|
42 |
12 |
4 |
USA |
NO |
|
23 |
4 |
6 |
N |
NO |
|
52 |
4 |
4 |
USA |
NO |
|
43 |
21 |
8 |
USA |
YES |
|
44 |
14 |
5 |
UK |
NO |
|
66 |
3 |
7 |
N |
YES |
|
35 |
14 |
9 |
UK |
YES |
|
52 |
13 |
7 |
N |
YES |
|
35 |
5 |
9 |
N |
YES |
|
24 |
3 |
5 |
USA |
NO |
|
18 |
3 |
7 |
UK |
YES |
|
45 |
9 |
9 |
UK |
YES |
ตอนนี้จากชุดข้อมูลนี้ Python สามารถสร้างแผนผังการตัดสินใจที่สามารถใช้ในการตัดสินใจว่ารายการ(List)ใหม่ใด ๆ ที่ควรค่าแก่การเข้าร่วม
มันทำงานยังไง?
ขั้นแรกให้ import โมดูลที่นักเรียนต้องการและอ่านชุดข้อมูลด้วย pandas
ตัวอย่าง
อ่านและพิมพ์ชุดข้อมูล
|
import pandas |
ต้นไม้ตัดสินใจข้อมูลทั้งหมดจะต้องเป็นตัวเลข เราต้องแปลงคอลัมน์ที่ไม่ใช่ตัวเลข 'Nationality' และ 'Go' เป็นค่าตัวเลข Pandas มีเมธอด map () ที่ใช้พจนานุกรมพร้อมข้อมูลเกี่ยวกับวิธีการแปลงค่า
|
{'UK': 0, 'USA': 1, 'N': 2} |
หมายถึงแปลงค่า 'UK' เป็น 0 'USA' เป็น 1 และ 'N' เป็น 2
ตัวอย่าง
เปลี่ยนค่าสตริงเป็นค่าตัวเลข
จากนั้นเราต้องแยกคอลัมน์คุณสมบัติออกจากคอลัมน์เป้าหมาย
|
import pandas |
ผลลัพธ์
|
C:\Users\My Name>python demo_ml_dtree2.py |
คอลัมน์คุณสมบัติคือคอลัมน์ที่เราพยายามคาดการณ์และคอลัมน์เป้าหมายคือคอลัมน์ที่มีค่าที่เราพยายามคาดการณ์
ตัวอย่าง
X คือคอลัมน์คุณสมบัติ y คือคอลัมน์เป้าหมาย
|
import pandas |
ผลลัพธ์
|
C:\Users\My Name>python demo_ml_dtree3.py |
ตอนนี้เราสามารถสร้างแผนผังการตัดสินใจที่แท้จริงพอดีกับรายละเอียดของเราและบันทึกไฟล์. png บนคอมพิวเตอร์
ตัวอย่าง
สร้างต้นไม้ตัดสินใจบันทึกเป็นภาพและแสดงภาพ
|
import pandas |
อธิบายผล
แผนผังการตัดสินใจใช้การตัดสินใจก่อนหน้าของนักเรียนในการคำนวณราคาต่อรองสำหรับนักเรียนที่ต้องการไปดูนักแสดงตลกหรือไม่
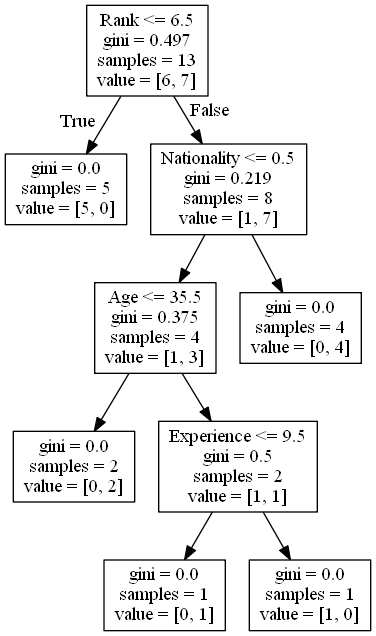
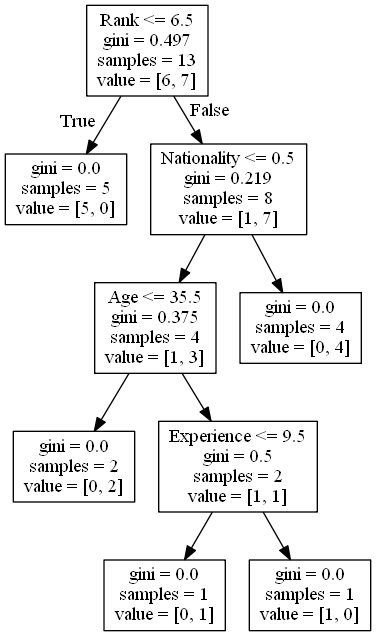
ให้เราอ่านแง่มุมต่าง ๆ ของแผนผังการตัดสินใจ
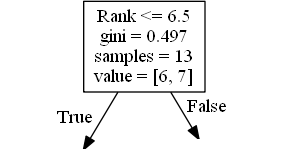
Rank
Rank <= 6.5 หมายความว่านักแสดงตลกทุกคนที่มีระดับ 6.5 หรือต่ำกว่าจะตามลูกศรจริง (ไปทางซ้าย) และที่เหลือจะตามลูกศรปลอม (ไปทางขวา)
gini = 0.497 หมายถึงคุณภาพของการแยกและเป็นจำนวนเสมอระหว่าง 0.0 และ 0.5 โดยที่ 0.0 จะหมายถึงตัวอย่างทั้งหมดได้ผลลัพธ์เหมือนกันและ 0.5 หมายถึงการแยกเสร็จตรงกลาง
samples = 13 หมายความว่ามีนักแสดงตลก 13 คนที่มาถึงจุดนี้ในการตัดสินใจซึ่งทั้งหมดเป็นเพราะพวกเขาเป็นขั้นตอนแรก
value = [6, 7] หมายความว่านักแสดงตลก 13 คนนี้ 6 คนจะได้รับ "ไม่" และ 7 จะได้รับ "GO"
Gini
มีหลายวิธีในการแยกตัวอย่างเราใช้วิธี GINI ในบทช่วยสอนนี้ วิธีการ Gini ใช้สูตรนี้
Gini = 1 - (x / n) 2 - (y / n) 2 โดยที่ x คือจำนวนคำตอบเชิงบวก ("GO"), n คือจำนวนตัวอย่างและ y คือจำนวนคำตอบเชิงลบ ("ไม่") ซึ่งให้การคำนวณนี้กับเรา 1 - (7/13) 2 - (6/13) 2 = 0.497
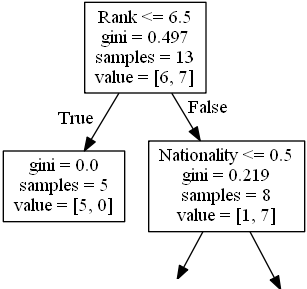
ขั้นตอนต่อไปมีสองกล่องหนึ่งกล่องสำหรับนักแสดงตลกที่มี 'อันดับ' 6.5 หรือต่ำกว่าและหนึ่งกล่องที่เหลือ
True - นักแสดงตลก 5 คนจบที่นี่
gini = 0.0 หมายถึงตัวอย่างทั้งหมดได้ผลลัพธ์เหมือนกัน
ตัวอย่าง = 5 หมายความว่ามีนักแสดงตลก 5 คนเหลืออยู่ในสาขานี้ (5 นักแสดงตลกที่มีอันดับ 6.5 หรือต่ำกว่า)
value = [5, 0] หมายความว่า 5 จะได้รับ "ไม่" และ 0 จะได้รับ "GO"
False - 8 นักแสดงตลกต่อไป
Nationality
Nationality <= 0.5 หมายความว่านักแสดงตลกที่มีค่าสัญชาติน้อยกว่า 0.5 จะตามลูกศรไปทางซ้าย (ซึ่งหมายถึงทุกคนจากสหราชอาณาจักร) และส่วนที่เหลือจะตามลูกศรไปทางขวา
gini = 0.219 หมายความว่าประมาณ 22% ของตัวอย่างจะไปในทิศทางเดียว
ตัวอย่าง = 8 หมายความว่ามีนักแสดงตลก 8 คนเหลืออยู่ในสาขานี้ (นักแสดงตลก 8 คนที่มีอันดับสูงกว่า 6.5)
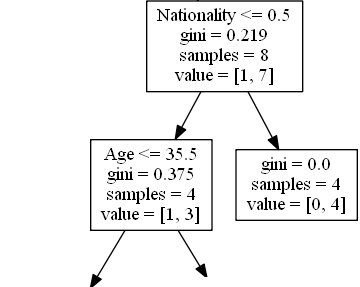
value = [1, 7] หมายความว่านักแสดงตลก 8 คนนี้ 1 คนจะได้รับ "ไม่" และ 7 จะได้รับ "GO"
True - นักแสดงตลก 4 คนดำเนินการต่อ
Age
Age <= 35.5 หมายถึงนักแสดงตลกที่อายุ 35.5 ปีหรือต่ำกว่าจะตามลูกศรไปทางซ้ายและคนที่เหลือจะตามลูกศรไปทางขวา
gini = 0.375 หมายความว่ากลุ่มตัวอย่างประมาณ 37,5% จะไปในทิศทางเดียว
ตัวอย่าง = 4 หมายความว่ามีนักแสดงตลก 4 คนเหลืออยู่ในสาขานี้ (นักแสดงตลก 4 คนจากสหราชอาณาจักร)
value = [1, 3] หมายความว่านักแสดงตลก 4 คนนี้ 1 คนจะได้รับ "ไม่" และ 3 จะได้รับ "GO"
False - 4 นักแสดงตลกจบที่นี่
gini = 0.0 หมายถึงตัวอย่างทั้งหมดได้ผลลัพธ์เหมือนกัน
ตัวอย่าง = 4 หมายความว่ามีนักแสดงตลก 4 คนเหลืออยู่ในสาขานี้ (นักแสดงตลก 4 คนที่ไม่ได้มาจากสหราชอาณาจักร)
value = [0, 4] หมายความว่านักแสดงตลก 4 คนเหล่านี้ 0 จะได้รับ "ไม่" และ 4 จะได้รับ "GO"
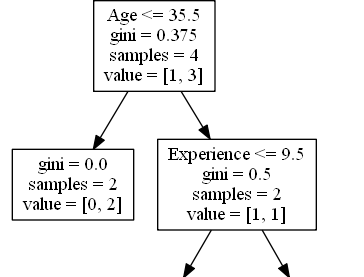
True - นักแสดงตลก 2 คนสิ้นสุดที่นี่
gini = 0.0 หมายถึงตัวอย่างทั้งหมดได้ผลลัพธ์เหมือนกัน
ตัวอย่าง = 2 หมายความว่ามีนักแสดงตลก 2 คนเหลืออยู่ในสาขานี้ (นักแสดงตลก 2 คนที่อายุ 35.5 ปีหรือน้อยกว่า)
value = [0, 2] หมายความว่านักแสดงตลก 2 คนนี้ 0 จะได้รับ "ไม่" และ 2 จะได้รับ "GO"
False - นักแสดงตลก 2 คนดำเนินการต่อ
Experience
Experience <= 9.5 หมายความว่านักแสดงตลกที่มีประสบการณ์ 9.5 ปีขึ้นไปจะตามลูกศรไปทางซ้ายและคนที่เหลือจะตามลูกศรไปทางขวา
gini = 0.5 หมายความว่า 50% ของตัวอย่างจะไปในทิศทางเดียว
ตัวอย่าง = 2 หมายความว่ามีนักแสดงตลก 2 คนเหลืออยู่ในสาขานี้ (2 นักแสดงตลกที่มีอายุมากกว่า 35.5)
value = [1, 1] หมายความว่านักแสดงตลก 2 คนนี้ 1 คนจะได้รับ "ไม่" และ 1 จะได้รับ "GO"
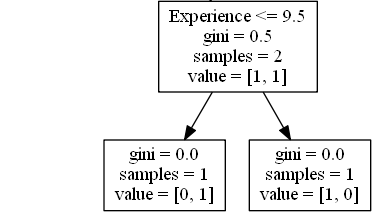
ทำนายค่า
เราสามารถใช้แผนภูมิการตัดสินใจเพื่อทำนายค่าใหม่
ตัวอย่าง: ผมควรไปดูรายการที่นำแสดงโดยนักแสดงตลกชาวอเมริกันอายุ 40 ปีมีประสบการณ์ 10 ปีและอันดับตลก 7 รายการหรือไม่
ตัวอย่าง
ใช้วิธีการpredict() เพื่อคาดการณ์ค่าใหม่
|
import pandas |
ผลลัพธ์
|
C:\Users\My Name>python demo_ml_dtree_predict1.py |
ผลลัพธ์ที่แตกต่าง
นักเรียนจะเห็นว่าแผนผังการตัดสินใจให้ผลลัพธ์ที่แตกต่าง หากนักเรียนใช้เวลามากพอแม้ว่านักเรียนจะป้อนด้วยข้อมูลเดียวกัน นั่นเป็นเพราะต้นไม้การตัดสินใจไม่ได้ให้คำตอบที่แน่นอน 100% มันขึ้นอยู่กับความน่าจะเป็นของผลลัพธ์และคำตอบจะแตกต่างกันไป
แปลจากhttps://www.w3schools.com/python/python_ml_decision_tree.asp
Tag ที่น่าสนใจ: machine_learning decision_tree programming_tutor python_tutorial numpy expert decision_making data_analysis programming_language expert_programming_tutor classification tree_structure decision_making_process data_science algorithm
หากมีข้อผิดพลาด/ต้องการพูดคุยเพิ่มเติมเกี่ยวกับบทความนี้ กรุณาแจ้งที่ http://m.me/Expert.Programming.Tutor
085-350-7540 (DTAC)
084-88-00-255 (AIS)
026-111-618
หรือทาง EMAIL: NTPRINTF@GMAIL.COM

Copyright (c) 2013 expert-programming-tutor.com. All rights reserved. | 085-350-7540 | 084-88-00-255 | ntprintf@gmail.com