สมัครเรียนโทร. 085-350-7540 , 084-88-00-255 , ntprintf@gmail.com
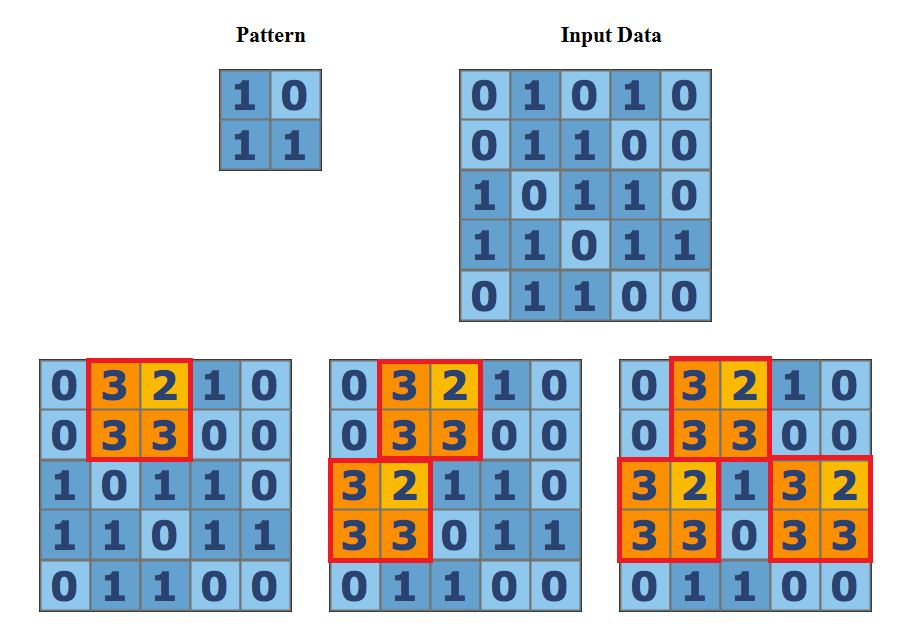
Machine Learning เป็นสาขาหนึ่งของปัญญาประดิษฐ์ที่พัฒนามาจากการ ศึกษาการรู้การจำ รูปแบบ Pattern Recognition เกี่ยวข้องกับการศึกษาและการสร้างอัลกอริทึมที่สามารถ เรียนรู้ข้อมูลและทำนายข้อมูลได้ อัลกอริทึมนั้นจะทำงานโดยอาศัยโมเดล ที่สร้าง มาจากชุดข้อมูลตัวอย่างขาเข้า (Training Data )เพื่อการทำนาย (Predict)หรือตัดสินใจในภายหลังแทนที่จะ ทำงานตามลำดับของคำสั่งโปรแกรมคอมพิวเตอร์
กล่าวคือ ปกติแล้ว เราเขียนโปรแกรม Computer ก็คือ การสั่งให้ Computer ทำงานตามคำสั่งที่ผู้เขียนโปรแกรมสั่งให้ทำแบบเฉพาะเจาะจงแต่ใน Machine Learning นี้เราฝันถึง Computer ที่มีความฉลาดมากยิ่งขึ้นซึ่งสามารถทำงานได้เองโดยไม่ต้องมีผู้สั่งมันทำแบบเฉพาะเจาะจง แต่จำเป็นต้องมีการสอนมันมันให้รู้ว่านี่คือ อินพุท นี้คือ เอาพุท ให้ Computer ไปหาวิธีตรงกลางเอาเอง
Machine Learning มีความเกี่ยวข้องอย่างมากกับวิชาสถิติ เนื่องจากทั้ง 2 สาขา ศึกษาการวิเคราะห์ข้อมูลเพื่อการทำนายเช่นกัน นอกจากนี้ยังมีความสัมพันธ์ กับสาขาการหาค่าเหมาะที่สุดในทางคณิตศาสตร์ (Mathematical Optimization)ในแง่ของวิธีการ ทฤษฎีและการ ประยุกต์ใช้ Machine Learning สามารถนำไปประยุกต์ใช้งานได้หลากหลาย ไม่ว่าจะเป็นการกรองอีเมล์ขยะ การรู้จำตัวอักษร เครื่องมือค้นหา และคอมพิวเตอร์วิทัศน์
การเรียนรู้ของเครื่อง สามารถแบ่งได้เป็น 3 ประเภท ตามประเภทของ"ข้อมูลฝึก" (Training Data )หรือ "ข้อมูลขาเข้า" ได้ดังนี้
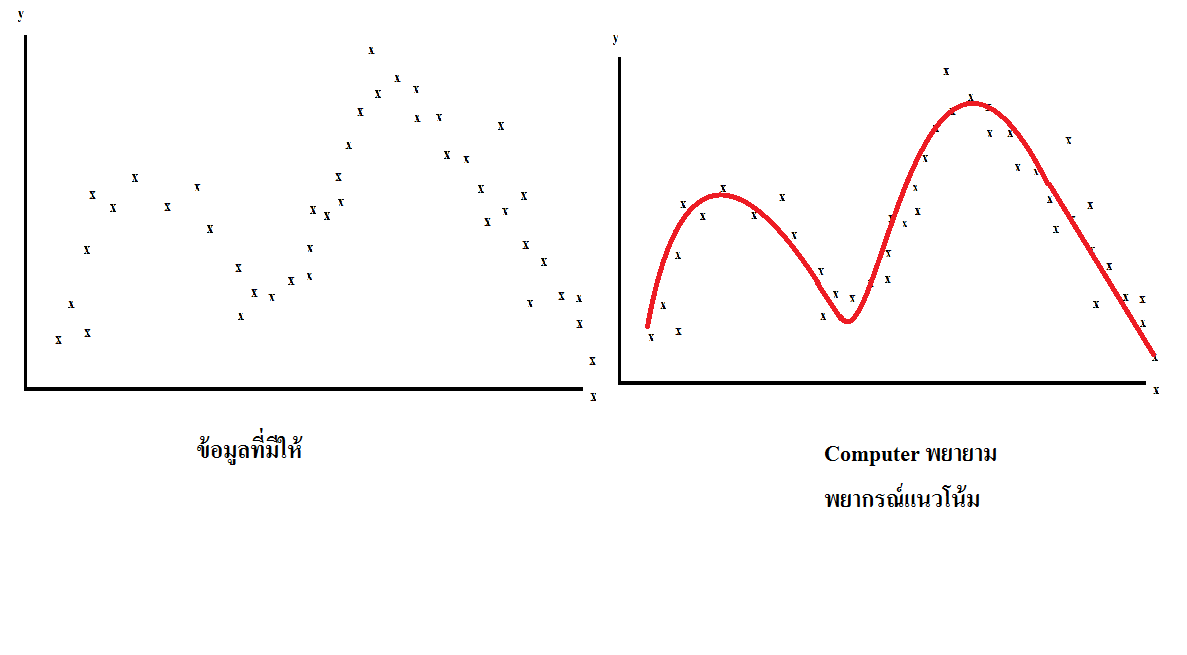
การเรียนรู้แบบมีผู้สอน (supervised learning) ข้อมูลตัวอย่างและผลลัพธ์ที่ "ผู้สอน" ต้องการ ถูกป้อนเข้าสู่คอมพิวเตอร์ เป้าหมาย คือ การสร้างกฎ ทั่วไปที่สามารถเชื่อมโยงข้อมูลขาเข้ากับขาออกได้
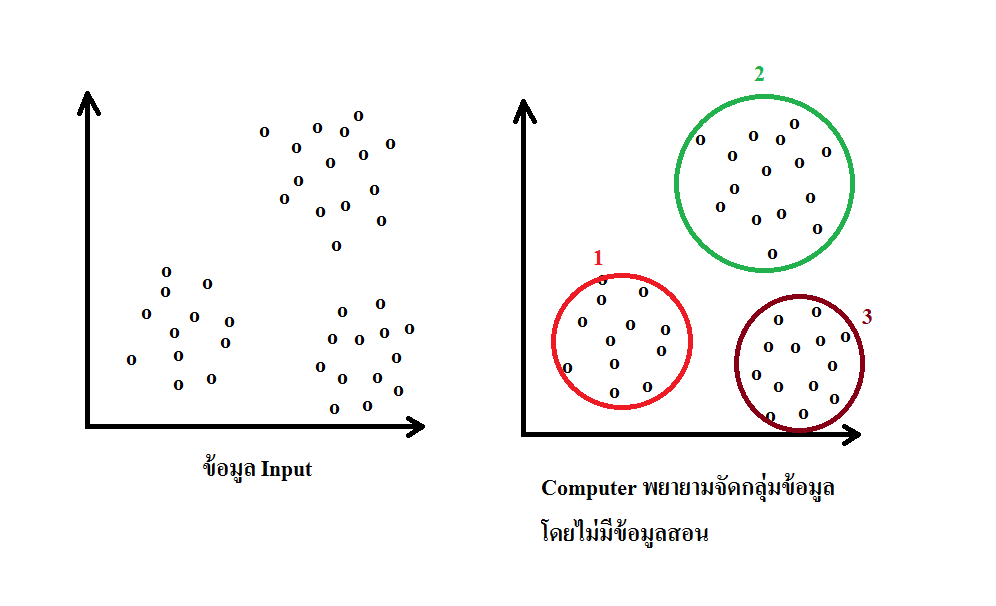
การเรียนรู้แบบไม่มีผู้สอน (unsupervised learning) ไม่มีการทำฉลากใดๆ และให้คอมพิวเตอร์หาโครงสร้างของข้อมูลขาเข้าเอง
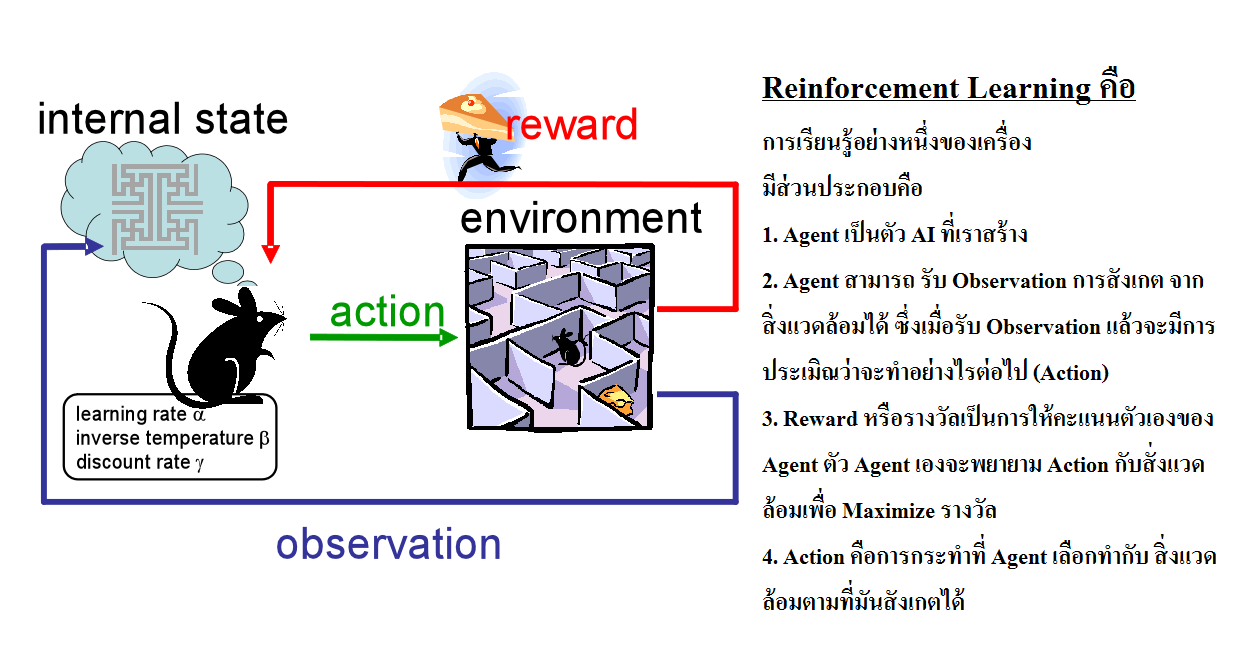
การเรียนรู้แบบเสริมกำลัง (reinforcement learning) คอมพิวเตอร์มี ปฏิสัมพันธ์กับสิ่งแวดล้อมที่เปลี่ยนไปตลอดเวลาโดย คอมพิวเตอร์จะต้อง ทำงานบางอย่าง (เช่น ขับรถ) โดยที่ไม่มี"ผู้สอน"คอย บอกอย่างจริงจัง ว่าวิธีการที่ทำอยู่นั้นเข้าใกล้เป้าหมายแล้วหรือไม่ ตัวอย่าง เช่น การเรียนรู้ เพื่อเล่นเกม
การเรียนรู้แบบกึ่งมีผู้สอน (semi supervised Learning) "ผู้สอน"จะไม่สอน อย่างสมบูรณ์ คือ บางข้อมูลในเซ็ตการสอนนั้นขาดข้อมูลขาออก
ทรานดักชัน (transduction) เป็นกรณีพิเศษของการเรียนรู้แบบกึ่งมีผู้สอน คือ ใช้ชุดตัวอย่างที่มีทั้งฉลากและไม่มีฉลากในการเรียนรู้ แต่จุดประสงค์ ไม่ใช่การสร้างแบบจำลอง แต่เป็นการใส่ฉลากให้กับตัวอย่างที่ไม่มีฉลากที่ ใช้ในการฝึกสอน เนื่องจากการเรียนรู้แบบนี้ไม่มีแบบจำลองจึงไม่สามารถ นำไปใช้กับข้อมูลชุดใหม่ได้โดยตรง
การเรียนวิธีการเรียน (learning to learn, meta-learning) เป็นวิธีที่จะเรียน วิธีการเรียนรู้ของตนเอง โดยปรับปรุง inductive bias ที่เป็นข้อสมมติฐานที่ อัลกอริทึมใช้ในการเรียนรู้จากประสบการณ์ที่ผ่านมา
นอกจากนี้ Machine Learning ยังสามารถแบ่งประเภทของ"งาน"ได้ตาม "ข้อมูลขา ออก" จาก ระบบที่เครื่องจักรได้เรียนรู้แล้ว เป็นหลายประเภท ดังนี้
Machine Learning ที่ใช้ในการแบ่งประเภทข้อมูล (classification) ข้อมูลขาเข้าถูกแบ่งออกเป็น หลายประเภทหรือ class และผู้เรียนจะต้องสร้างโมเดลที่สามารถกำหนด ประเภทให้กับข้อมูลใหม่ที่ไม่เคยเห็นมาก่อนได้ โดยปกติแล้วจะทำโดยวิธี การเรียนรู้แบบมีผู้สอน ได้แก่ การกรองอีเมล์ขยะ โดยอีเมล์จะถูกแบ่งเป็น ประเภท"ขยะ"และ"ไม่ใช่ขยะ"
การวิเคราะห์การถดถอย (regression) ใช้หลักการเดียวกับการแบ่งประเภท ข้อมูล แต่ข้อมูลขาออกเป็นลักษณะต่อเนื่องมากกว่าเป็นประเภทแยกกัน
การแบ่งกลุ่มข้อมูล (clustering) เป้าหมาย คือ การแบ่งข้อมูลขาเข้าเป็น กลุ่มๆ โดยอัลกอริทึมจะไม่ทราบกลุ่มดังกล่าวล่วงหน้า (ไม่เหมือนกับการ แบ่งประเภทข้อมูล) โดยปกติแล้วมักเป็นการเรียนรู้แบบไม่มีผู้สอน
การประเมินความหนาแน่น (density estimation) เป็นการหาการกระจาย ของข้อมูลในมิติบางมิติ
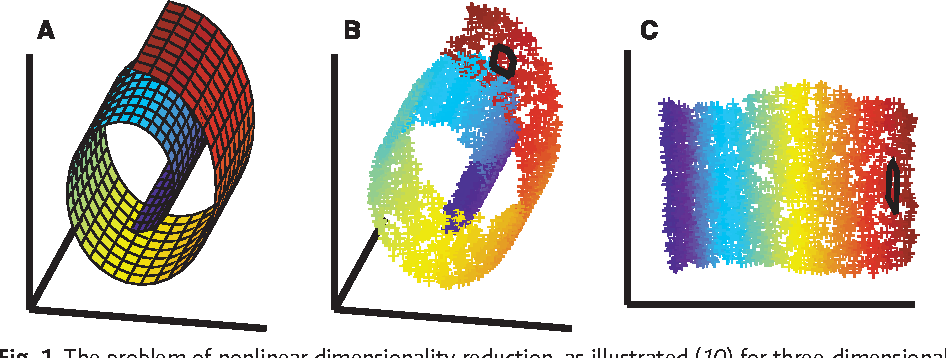
การลดขนาดของมิติ (dimensionality reduction) เป็นการเชื่อมโยงข้อมูล หลายมิติไปสู่มิติที่ต่ำกว่า
ศาสตร์ด้าน Machine Learning เติบโตไปพร้อมๆกับปัญญาประดิษฐ์ ในความเป็นจริง Machine Learning มีมาตั้งแต่ยุคแรกๆของปัญญาประดิษฐ์แล้ว นักวิทยาศาสตร์หลายคนสนใจการสร้างเครื่องจักรที่สามารถเรียนรู้จากข้อมูลได้ จึงเริ่มทดลองวิธีการหลายๆอย่าง ที่ชัดสุด คือ โครงข่ายประสาทเทียม เวลาต่อมา ได้มีการคิดค้นโมเดลเชิงเส้นทั่วไปจากหลักการทางสถิติศาสตร์ ไปจนถึงการพัฒนา วิธีการให้เหตุผลตามหลักความน่าจะเป็น โดยเฉพาะในการประยุกต์ด้านการวินิจฉัย โรคอัตโนมัติ อย่างไรก็ตาม นักวิจัยในสายปัญญาประดิษฐ์ยุคต่อมาเริ่มหันมาให้ ความสำคัญกับตรรกศาสตร์และใช้วิธีการทางการแทนความรู้มากขึ้น จนทำให้ ปัญญาประดิษฐ์เริ่มแยกตัวออกจากศาสตร์ Machine Learning จากนั้นเริ่มมี การใช้หลักการความน่าจะเป็นมากขึ้นในการดึงและการแทนข้อมูล ต่อมาระบบ ผู้เชี่ยวชาญเริ่มโดดเด่นในสายของปัญญาประดิษฐ์จนหมดยุคของการใช้หลักสถิติ มีงานวิจัยด้านการเรียนรู้เชิงสัญลักษณ์และบนพื้นฐานของฐานความรู้ออกมา
เรื่อยๆจนศาสตร์ด้านการโปรแกรมตรรกะเชิงอุปนัยได้ถือกำเนิดขึ้นมา แต่งานด้าน สถิติก็ยังถือว่ามีบทบาทมากนอกสาขาของปัญญาประดิษฐ์ เช่น การรู้การจำแบบ และการค้นคืนสารสนเทศ นักวิจัยสายปัญญาประดิษฐ์และนักวิทยาศาสตร์ คอมพิวเตอร์ได้ทิ้งงานวิจัยด้านโครงข่ายประสาทเทียมไปในเวลาเดียวกัน แต่ก็ยังมี นักคณิตศาสตร์บางคนที่ยังพัฒนาโครงข่ายประสาทเทียมต่อไป จนกระทั่งได้ค้นพบ หลักการการแพร่คืนย้อนกลับของโครงข่ายประสาทเทียมที่ประสบความสำเร็จ มากมายในเวลาต่อมา
Machine Learning เน้นเรื่องการพยากรณ์ข้อมูลจากคุณสมบัติที่"รู้"แล้วที่ ได้เรียนรู้มาจากข้อมูลชุดสอน
Machine Learning ยังมีความคล้ายคลึงกับการหาค่าเหมาะที่สุด (optimization) นั่นคือ การเรียนรู้หลายอย่างมักจะถูกจัดให้อยู่ในรูปแบบของการ หาค่าที่น้อยที่สุดของฟังก์ชันการสูญเสียบางอย่างจากข้อมูลชุดสอน ฟังก์ชันการ สูญเสีย หมายถึง ความแตกต่างระหว่างสิ่งที่พยากรณ์ไว้กับสิ่งที่เป็นจริง
การเรียนรู้ต้นไม้ตัดสินใจ (decision tree learning)
ใช้ต้นไม้ตัดสินใจในการสร้างโมเดลที่พยากรณ์ได้ ซึ่งจะเชื่อมโยงข้อมูลสังเกต การณ์เข้ากับข้อมูลปลายทาง
กฎความสัมพันธ์ (association rule learning)
เป็นวิธีการหาความสัมพันธ์ที่น่าสนใจจากตัวแปรในฐานข้อมูลขนาดใหญ่
โครงข่ายประสาทเทียม (artificial neural networks)
เป็นอัลกอริทึมที่ได้แรงบันดาลใจมาจากโครงสร้างและการทำงานของเซลล์ประสาทในสมอง การคำนวณของโครงข่ายประสาทเทียมถูกสร้างเป็นโครงสร้างของการ เชื่อมต่อของประสาทเทียมแต่ละตัว ประมวลผลข้อมูลโดยหลักการการเชื่อมต่อ โครงข่ายสมัยใหม่เป็นเครื่องวิเคราะห์ทางสถิติที่ไม่เป็นเชิงเส้น มักใช้ในการจำลอง ความสัมพันธ์ที่ซับซ้อนระหว่างข้อมูลขาเข้าและขาออก เพื่อหารูปแบบจากข้อมูล หรือเพื่อหาโครงสร้างทางสถิติระหว่างตัวแปรที่สำรวจ
การโปรแกรมตรรกะเชิงอุปนัย (inductive logic programming)
เป็นวิธีการเรียนรู้จากกฎโดยใช้การโปรแกรมตรรกะ เมื่อมีข้อมูลเบื้องหลังและกลุ่ม ของตัวอย่างที่เป็นฐานข้อมูลตรรกะแล้ว โปรแกรมจะหาโปรแกรมตรรกะที่ครอบ คลุมตัวอย่างบวกแต่ไม่ครอบคลุมตัวอย่างลบ
ซัพพอร์ตเวกเตอร์แมชชีน (support vector machines)
เป็นหนึ่งในวิธีการเรียนรู้แบบมีผู้สอน ใช้เพื่อการแบ่งประเภทข้อมูลและการ วิเคราะห์การถดถอย เมื่อมีข้อมูลฝึกมาให้และแต่ละข้อมูลถูกจัดอยู่ในประเภทใด ประเภทหนึ่งจากสองประเภท ซัพพอร์ตเวกเตอร์แมชชีนจะสร้างแบบจำลองที่ สามารถพยากรณ์ได้ว่าตัวอย่างใหม่นี้จะตกอยู่ในกลุ่มใด
การแบ่งกลุ่มข้อมูล (clustering)
เป็นการจัดกลุ่มของข้อมูลสำรวจให้ตกอยู่ในเซ็ตย่อย (เรียกว่า กลุ่ม หรือ cluster) โดยที่ข้อมูลที่อยู่ในกลุ่มเดียวกันจะมีความคล้ายกันตามเกณฑ์ที่ตั้งเอาไว้ ในข้อมูล ที่อยู่คนละกลุ่มจะมีความต่างกัน เทคนิคการแบ่งกลุ่มข้อมูลแต่ละเทคนิคก็มี สมมติฐานของโครงสร้างข้อมูลไม่เหมือนกัน โดยปกติแล้วมักจะมีการนิยาม การวัด ค่าความเหมือน การเกาะกลุ่มภายในและการแยกกันระหว่างกลุ่มที่แตกต่างกัน การแบ่งกลุ่มข้อมูลเป็นวิธีการเรียนรู้แบบไม่มีผู้สอนและเป็นวิธีที่ใช้กันทั่วไปใน การวิเคราะห์ข้อมูลทางสถิติ
เครือข่ายแบบเบย์ (Bayesian networks)
เป็นโมเดลความน่าจะเป็นเชิงกราฟที่แทนกลุ่มของตัวแปรสุ่มและความเป็นอิสระ แบบมีเงื่อนไขด้วยกราฟอวัฏจักรระบุทิศทาง เช่น สามารถใช้แทนความสัมพันธ์เชิง ความน่าจะเป็นระหว่างอาการแสดงกับโรคได้ เมื่อมีอาการแสดง เครือข่ายจะ คำนวณความน่าจะเป็นที่จะเป็นโรคแต่ละโรค มีหลายอัลกอริทึมที่สามารถอนุมาน และเรียนรู้ได้อย่างมีประสิทธิภาพ
การเรียนรู้แบบเสริมกำลัง (reinforcement learning)
พิจารณาว่า เอเยนต์ ควรจะมีการกระทำใดในสิ่งแวดล้อม เพื่อที่จะได้รางวัลสูงสุด อัลกอริทึมของการเรียนรู้แบบเสริมกำลังนี้พยายามจะหานโยบายที่เชื่อมโยง สถานะของโลกเข้ากับการกระทำที่เอเยนต์ควรจะทำในสถานะนั้นๆ การเรียนรู้นี้มี ความแตกต่างไปจากการเรียนรู้แบบมีผู้สอนตรงที่ว่า คอมพิวเตอร์จะไม่รู้เลยว่า อะไรถูกอะไรผิด คือ ไม่มีการบอกอย่างชัดเจนว่าการกระทำใดยังไม่ดี
การเรียนรู้ด้วยการแทน (representation learning)
การเรียนรู้บางอย่างโดยเฉพาะการเรียนรู้แบบไม่มีผู้สอนนั้นพยายามจะค้นหาการ แทนข้อมูลขาเข้าที่ดีขึ้นเมื่อมีชุดข้อมูลฝึก ได้แก่ การวิเคราะห์องค์ประกอบหลัก และการแบ่งกลุ่มข้อมูล อัลกอริทึมการเรียนรู้ด้วยการแทนมักจะเปลี่ยนข้อมูลไป ในรูปแบบที่มีประโยชน์แต่ยังคงรักษาสารสนเทศของข้อมูลเอาไว้ มักใช้ใน กระบวนการเตรียมข้อมูลก่อนจะแบ่งประเภทข้อมูลหรือพยากรณ์ ตัวอย่างอื่นๆ เช่น การเรียนรู้เชิงลึก
การเรียนรู้ด้วยความคล้าย (similarity and metric learning)
เครื่องจะมีตัวอย่างของคู่ที่ถูกมองว่าคล้ายมากและคู่ที่ถูกมองว่าคล้ายน้อย เครื่องจะต้องหาฟังก์ชันความคล้ายออกมาที่สามารถทำนายได้ว่าวัตถุใหม่นั้นมี ความคล้ายมากน้อยเพียงใด มักใช้ในระบบแนะนำ (recommendation system)
ขั้นตอนวิธีเชิงพันธุกรรม (genetic algorithms)
เป็นการค้นหาแบบฮิวริสติกที่เลียนแบบกระบวนการคัดเลือกตามธรรมชาติในช่วง วิวัฒนาการของสิ่งมีชีวิต โดยใช้เทคนิคการกลายพันธุ์ของยีนและการไขว้เปลี่ยน ของโครโมโซมในการหาประชากรที่น่าจะอยู่รอดเพื่อพาไปสู่คำตอบของปัญหาได้ เทคนิคทาง Machine Learning ช่วยปรับปรุงประสิทธิภาพของขั้นตอนวิธีเชิง พันธุกรรมและขั้นตอนวิธีเชิงวิวัฒนาการด้วยเช่นกัน
การเรียนรู้ของเครื่องสามารถประยุกต์ใช้งานได้หลากหลาย เช่น
References :
Tag ที่น่าสนใจ: machine_learning pattern_recognition supervised_learning unsupervised_learning reinforcement_learning classification regression clustering density_estimation dimensionality_reduction artificial_intelligence training_data data_prediction statistical_analysis
หากมีข้อผิดพลาด/ต้องการพูดคุยเพิ่มเติมเกี่ยวกับบทความนี้ กรุณาแจ้งที่ http://m.me/Expert.Programming.Tutor
085-350-7540 (DTAC)
084-88-00-255 (AIS)
026-111-618
หรือทาง EMAIL: NTPRINTF@GMAIL.COM

Copyright (c) 2013 expert-programming-tutor.com. All rights reserved. | 085-350-7540 | 084-88-00-255 | ntprintf@gmail.com